Streaming Engine to 5k+ Users (8) - Summary
· 8 min read

After a series of rigorous load tests, including smoke tests, a 1.5k Virtual Users (VUs) spike test, and a 5k VUs capacity test, the streaming engine architecture has proven its resilience and performance. Here is a summary of the journey, the bottlenecks discovered, and the solutions implemented.


Key Achievements at a Glance
5000 CCU Capacity Test
- 🚀 5,000 CCU Peak Capacity: Perfectly maintained 5,000 concurrent active WebSocket connections.
- ⚡ 14,000 ops/sec Broadcast: Handled massive throughput at peak capacity, pushing 2.6+ million updates in 10 minutes.
- 📉 30% Latency Improvement: Significantly improved real-time responsiveness, reducing P50 streaming latency from >1s down to 500ms.
- 🧠 Optimized Hardware Footprint (~2 CPU Cores): Reduced CPU usage by up to 10% (stabilizing at 2 cores), sustaining the absolute maximum load with high efficiency.
- 🛡️ Zero Resource Leaks & 33% Less RAM: Slashed memory consumption from 300MB to 200MB (a 33% reduction on BC11) while ensuring perfect Goroutine cleanup when 5,000 users abruptly disconnect.
| Metric | Before | After |
|---|---|---|
| CPU BC11(G): 2.2 -> 2 (10% reduction) BC15(Y): 2.1-> 2 (5% reduction) | 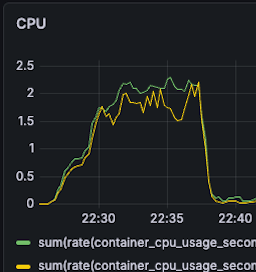 | 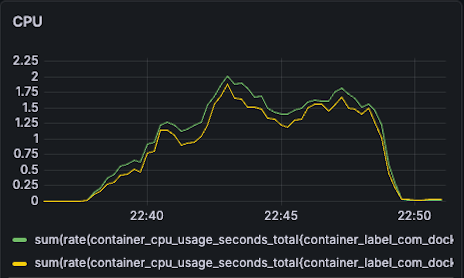 |
| Memory BC11(G): 300MB -> 200MB (33% reduction) BC15(Y): 512 MB -> 512 MB (0% reduction) | 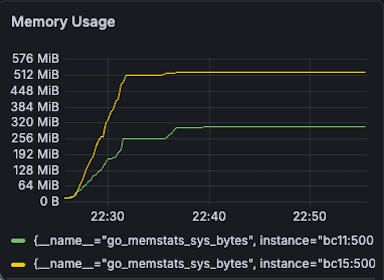 | 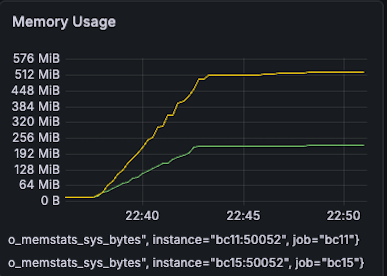 |
| P50 Streaming latency (Y) >1s -> 500ms (50% reduction) | 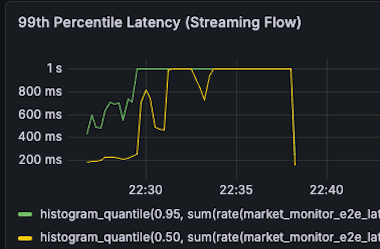 | 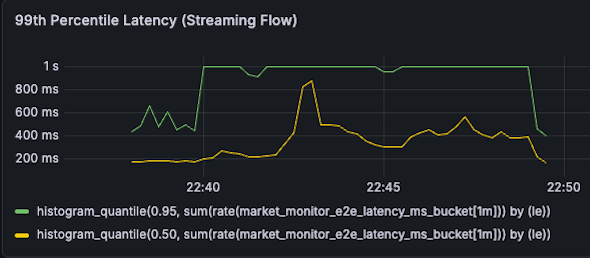 |
Capacity Test Results
- CPU
- BC11: 2.2 -> 2 (10% reduction)
- BC15: 2.1-> 2 (5% reduction)
- Ram
- BC11: 300MB -> 200MB (33% reduction)
- BC15: 512 MB -> 512 MB (0% reduction)
- P50 Streaming latency
- 1s -> 500ms (50% reduction)
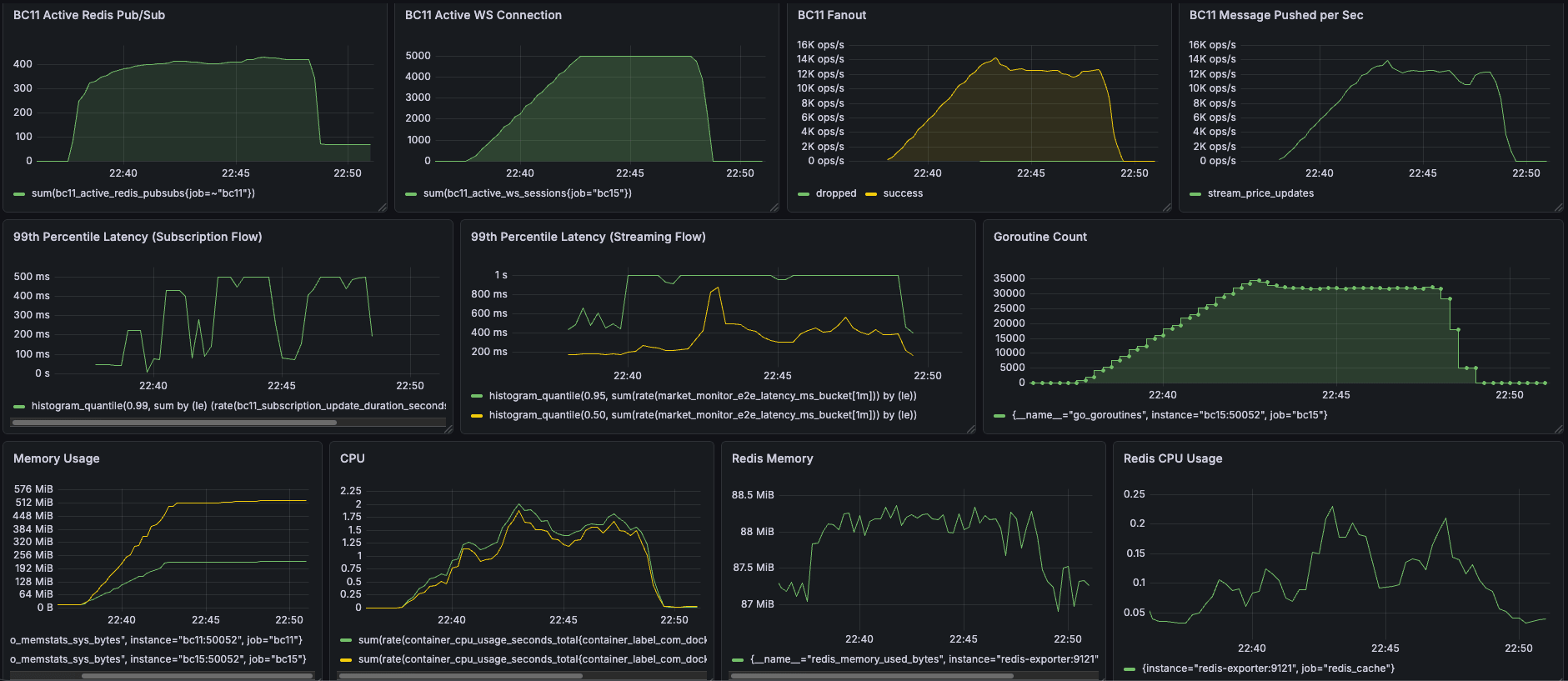
1500 CCU Sudden Spike Test
- 🚀 1,500 CCU Peak Capacity: Perfectly maintained 1,500 concurrent active WebSocket connections under sudden spike test conditions.
- 📉 Up to 40% Latency Reduction: Significantly improved real-time responsiveness under heavy load, slashing P99 streaming latency from 1s to 600ms (40% faster) and P99 subscription latency to 320ms (36% faster).
- 🧠 Optimized Hardware Footprint: Drastically improved compute efficiency, reducing CPU usage by up to 50% (stabilizing at just 0.6 to 0.8 cores) to sustain maximum load.
- 🛡️ Zero Leaks & Robust Resilience: Slashed peak Goroutine count by 76% (from 37k down to 9k) and memory consumption by 37% (270MB down to 170MB), ensuring perfect resource cleanup even when 1,500 users abruptly disconnect.
| Metric | Before | After |
|---|---|---|
| Memory BC11(G): 90MB -> 90MB (0% reduction) BC15(Y): 270MB -> 170MB (37% reduction) | 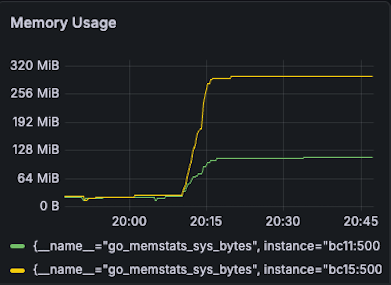 | 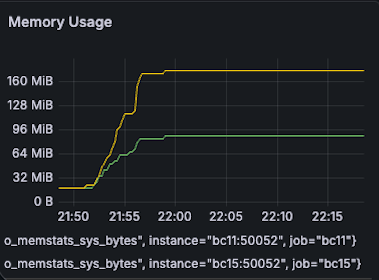 |
| CPU BC11(G): 1.2 -> 0.8 (33% reduction) BC15(Y): 1.2 -> 0.6 (50% reduction) | 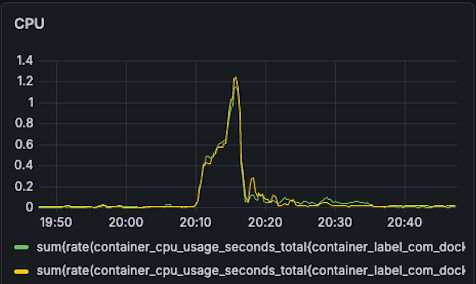 | 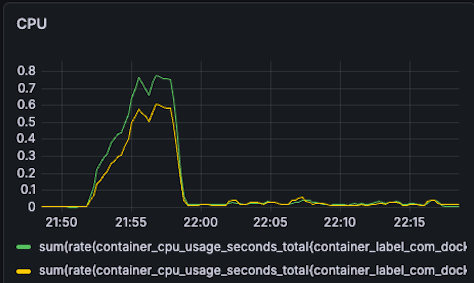 |
| Subscription P99 Latency 500ms -> 320ms (36% reduction) | 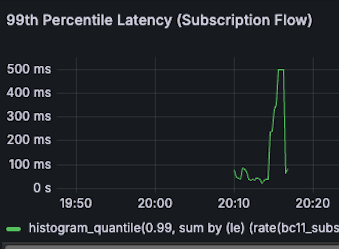 | 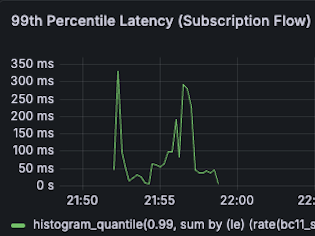 |
| Streaming P99 Latency 1s -> 600ms (40% reduction) | 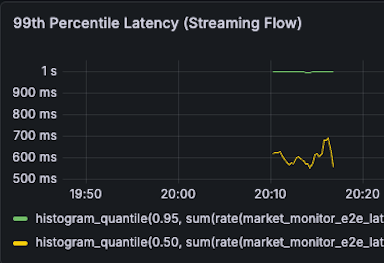 | 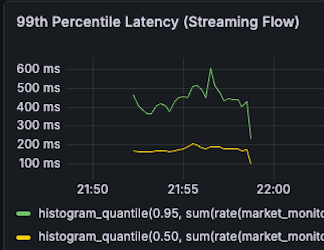 |
| Goroutine Count at peak 37000 -> 9000 (76% reduction) | 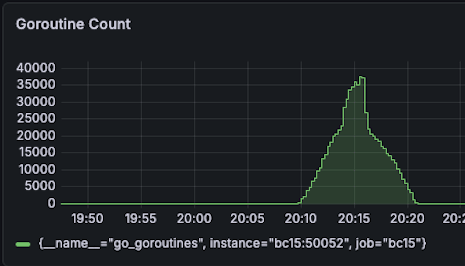 |  |
Spike Test Results
- Ram:
- BC11: 90MB -> 90MB
- BC15: 270MB -> 170MB (37% reduction)
- CPU
- BC11: 1.2 -> 0.8 (33% reduction)
- BC15: 1.2 -> 0.6 (50% reduction)
- Subscription P99 Latency
- 500ms -> 320ms (36% reduction)
- Streaming P99 Latency
- 1s -> 600ms (40% reduction)
- Goroutine Count at peak
- 37000 -> 9000 (76% reduction)
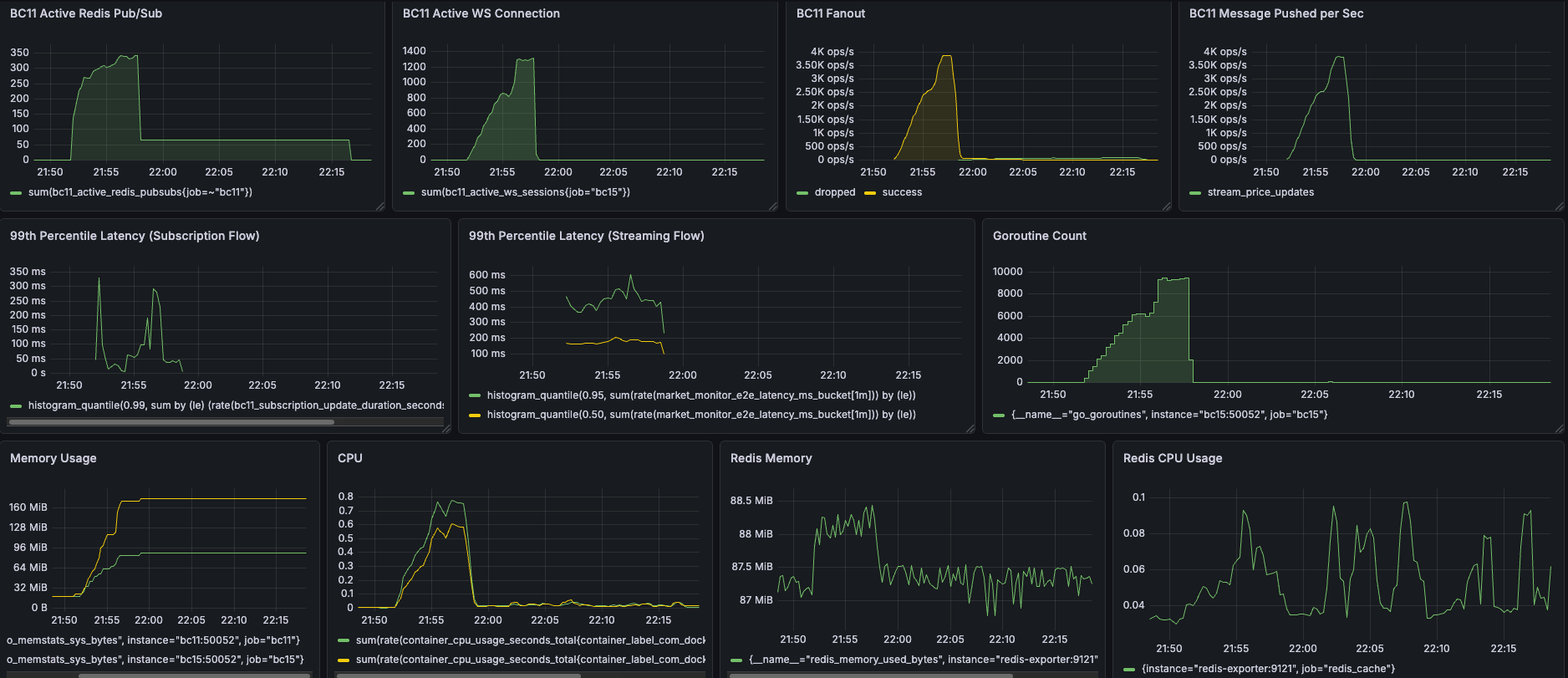
Load Test Results
- Capacity Test (5,000 VUs): Perfectly maintained 5,000 concurrent active WebSocket connections. The system successfully distributed over 260+ million real-time price updates within 10 minutes, with a peak broadcast rate of 14,000 ops/sec. It achieved this using an optimized hardware footprint of only ~2 CPU cores (a 10% reduction) and 200MB RAM (a 33% reduction). Furthermore, P50 streaming latency was reduced by 50% down to 500ms, with zero memory or goroutine leaks after the test ended.
- Spike Test (1,500 VUs): Successfully handled massive connection churns, proving the system's robust resilience under sudden traffic surges and drops. Compute efficiency was drastically improved, requiring only 0.6 to 0.8 CPU cores (up to 50% reduction) and slashing peak Goroutine count by 76% (from 37,000 down to 9,000). Real-time responsiveness was significantly enhanced, achieving a 320ms P99 subscription latency (36% faster) and 600ms P99 streaming latency (40% faster).
Note: I intentionally set up 200ms frequency to batch the price updates to simulate the real-world market volatility.
Challenges & Solutions
Throughout the testing phases, several critical concurrency and resource management issues were exposed and resolved:
1. Race Conditions & Panics
- Issue:
panic: close of closed channeloccurred when multiple goroutines (API, background cleanup, WebSocket close) attempted to deactivate the same session concurrently. - Solution: Made the
deactivateSessionfunction idempotent using a session-level lock (if !session.IsActive { return }) before cleaning up resources.
2. Resource & Goroutine Leaks
- Redis Pub/Sub Leak: Connections leaked when
stream.Send()errors bypassed the session deactivation. Fixed by ensuringdeactivateSessionis called within adeferstatement. - WebSocket Goroutine Leak: The API gateway accumulated up to 40k leaked goroutines for only 1.3k connections due to improper context cancellation and unhandled TCP drops. Fixed by:
- Returning and properly deferring the
cancelfunction from customWithTimeoutcontexts. - Implementing explicit
conn.Close()on context completion instead of relying on blocked actions inselectdefault cases. - Adding Ping/Pong handlers with read deadlines (
conn.SetReadDeadline) to gracefully detect and close dead connections that didn't send a TCP FIN packet.
- Returning and properly deferring the
- Long-tail Resource Leak: Calling
close(session.PriceStream)caused panics if background goroutines were still interacting with it. Fixed by usingcontext.CancelFuncto unblock receivers and letting the Garbage Collector (GC) safely reclaim the unclosed channels.
3. Performance Tuning & Micro-optimizations
- O(1) Map Lookup: Replaced the array-based
priceChannelsmanagement with a nested map (map[string]map[string]chan) keyed bysessionID. This O(1) deletion significantly reduced overhead and lock contention during high-churn disconnection events. - Timestamp Type Conversion: Avoided expensive string-to-int parsing (
strconv.ParseInt) by changing the Protobuf timestamp type toint64. This micro-optimization, combined with the structural changes, was the key driver in slashing the P99 latency down to 600ms and lowering overall CPU usage by up to 50%.
Key Takeaways
- Let GC Handle Data Channels: "Never close a channel from the receiver (Session) side. Only close it from the sender, or let GC handle it." Use Context to signal cancellations instead of explicitly closing data channels that might still have concurrent senders, avoiding
close of closed channelpanics. - Avoid Blocking in
select default: "In a loop, never put blocking functions (like network reads, channel receives) in the default case of a select!" It defeats the purpose of theselectstatement and blocks the goroutine from receiving the context cancellation signal. - Context Cancellation Responsibility: "Who calls, who is responsible for cancellation." Always defer the cancel function in the exact same scope where the context was created to guarantee execution.
- WebSocket Lifecycle Management: HTTP connections upgraded to WebSockets require explicit, manual closure. They do not automatically tear down when the HTTP context is done, nor do they reliably emit TCP FIN packets if the client abruptly disconnects or loses network. Always implement application-level Ping/Pong heartbeat and zombine cleanup mechanisms.
Check the series of posts:
- Streaming Engine to 5k+ Users (0) - Set up
- Streaming Engine to 5k+ Users (1) - Debugging a Race Condition in SessionManager.
- Streaming Engine to 5k+ Users (2) - Debugging Leaked Redis Pub/Sub Connections
- Streaming Engine to 5k+ Users (3) - Debugging Leaked Goroutine with Websocket
- Streaming Engine to 5k+ Users (4) - Shifting to Capacity Test
- Streaming Engine to 5k+ Users (5) - Performance Tuning
- Streaming Engine to 5k+ Users (6) - Micro-optimization
- Streaming Engine to 5k+ Users (7) - Debugging Long-tail Resource Leaks